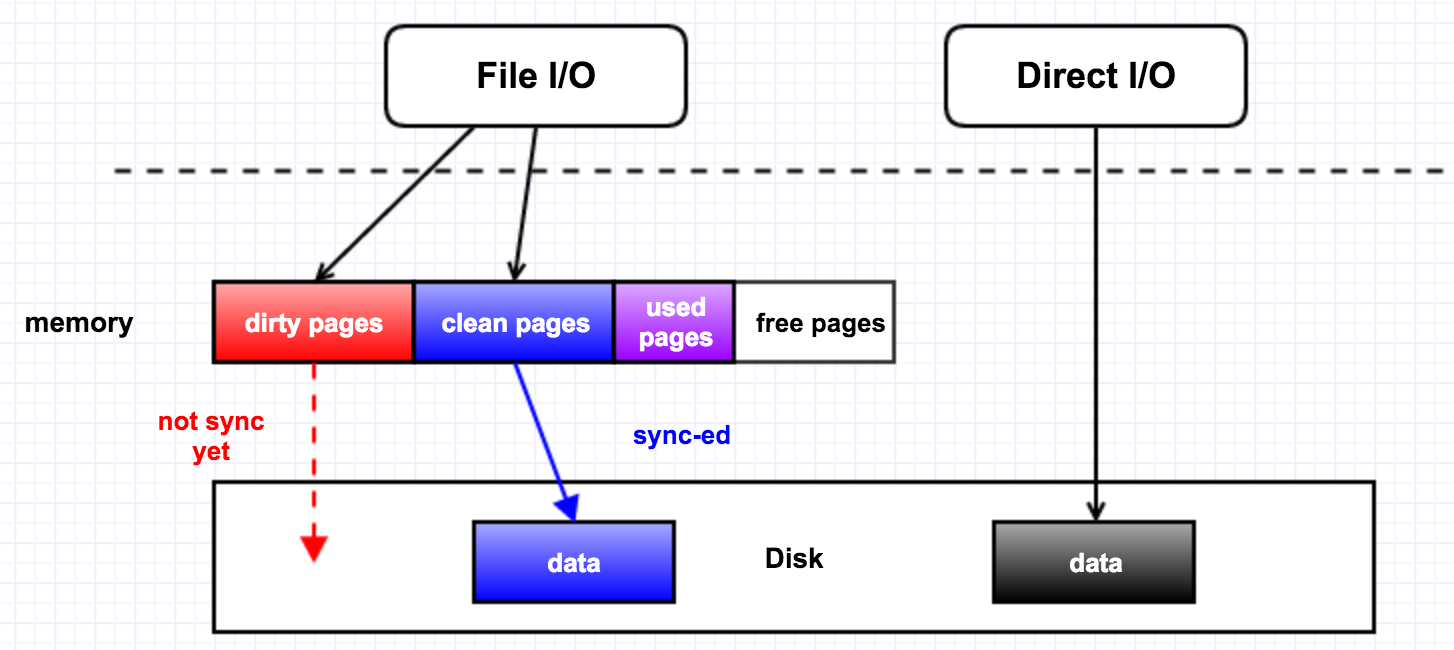
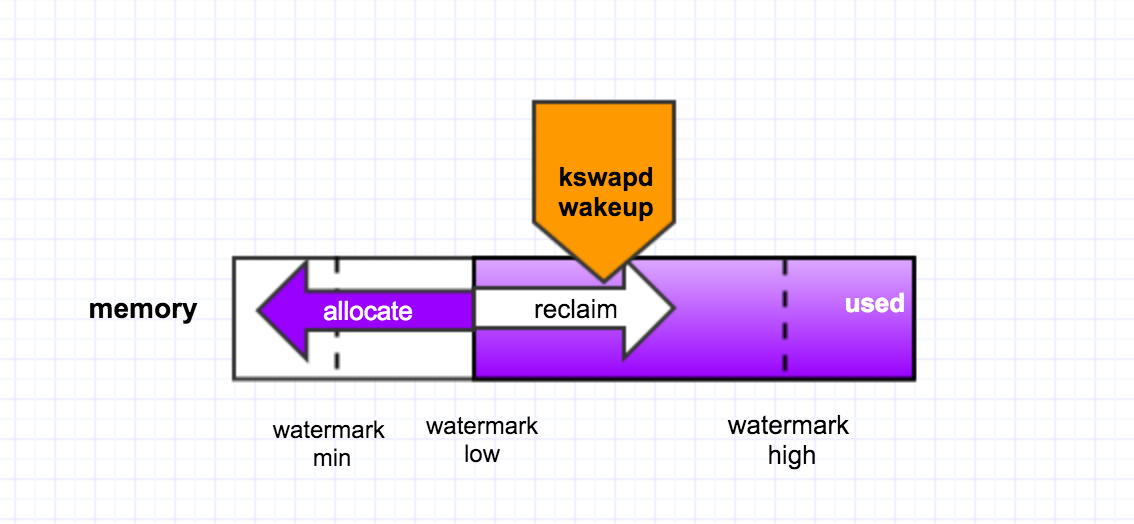
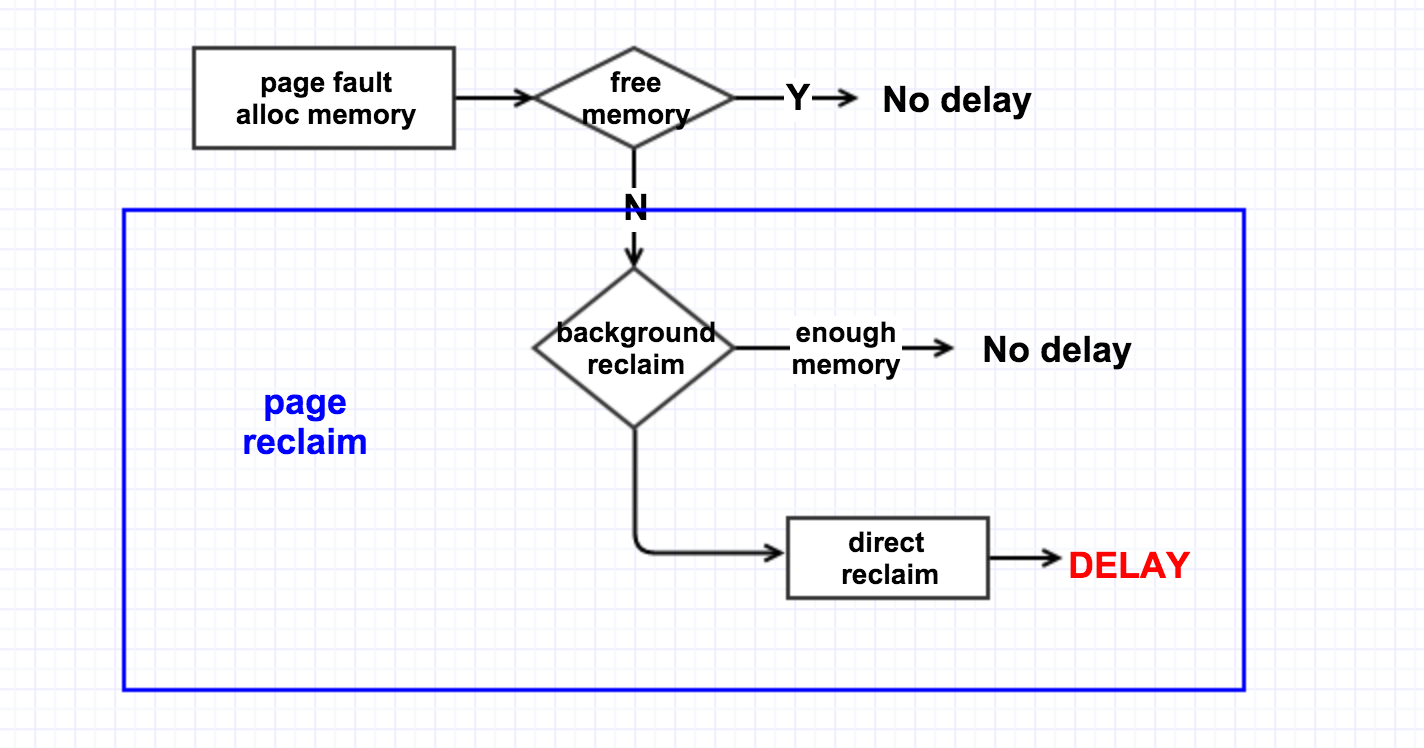
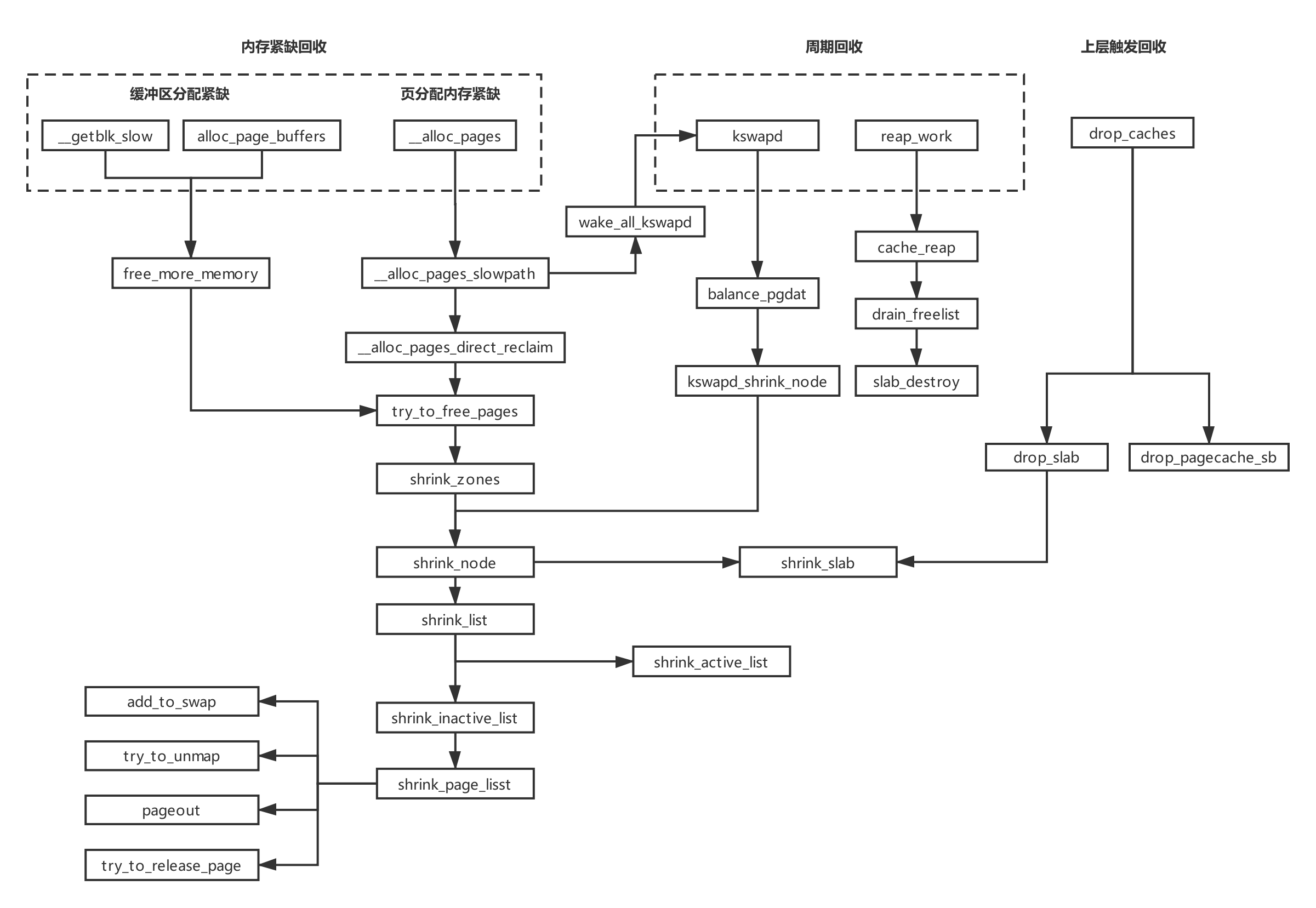
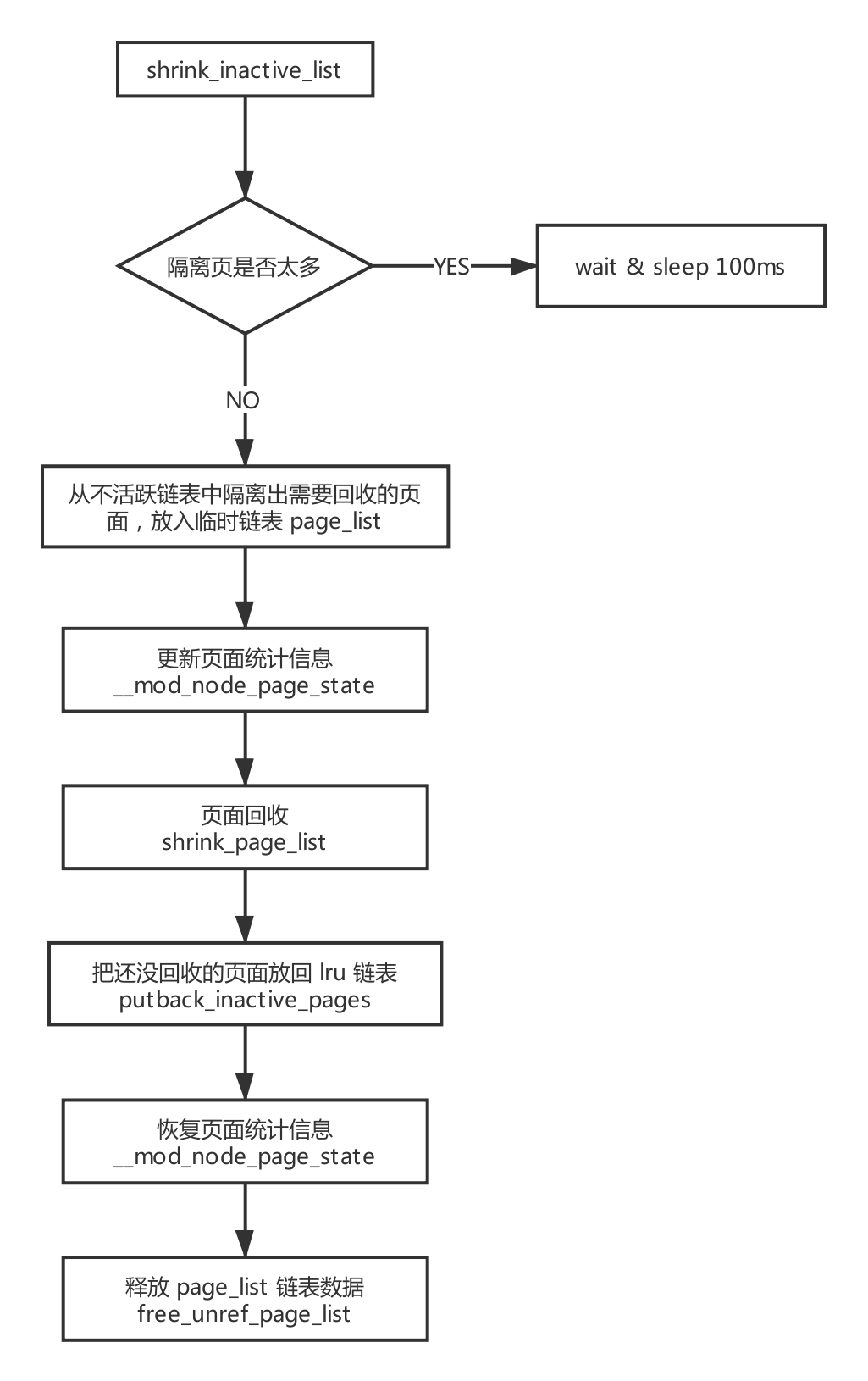
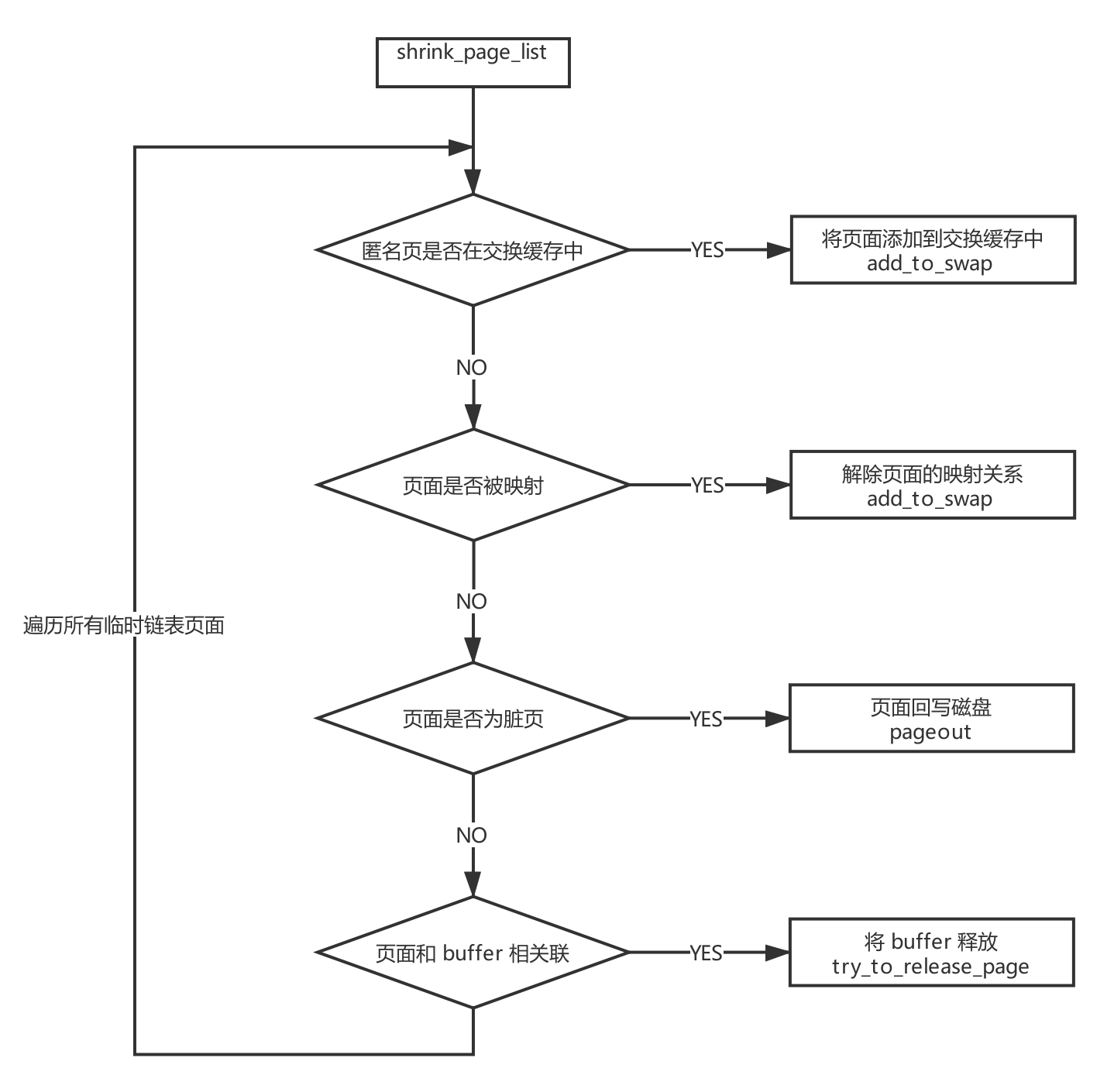
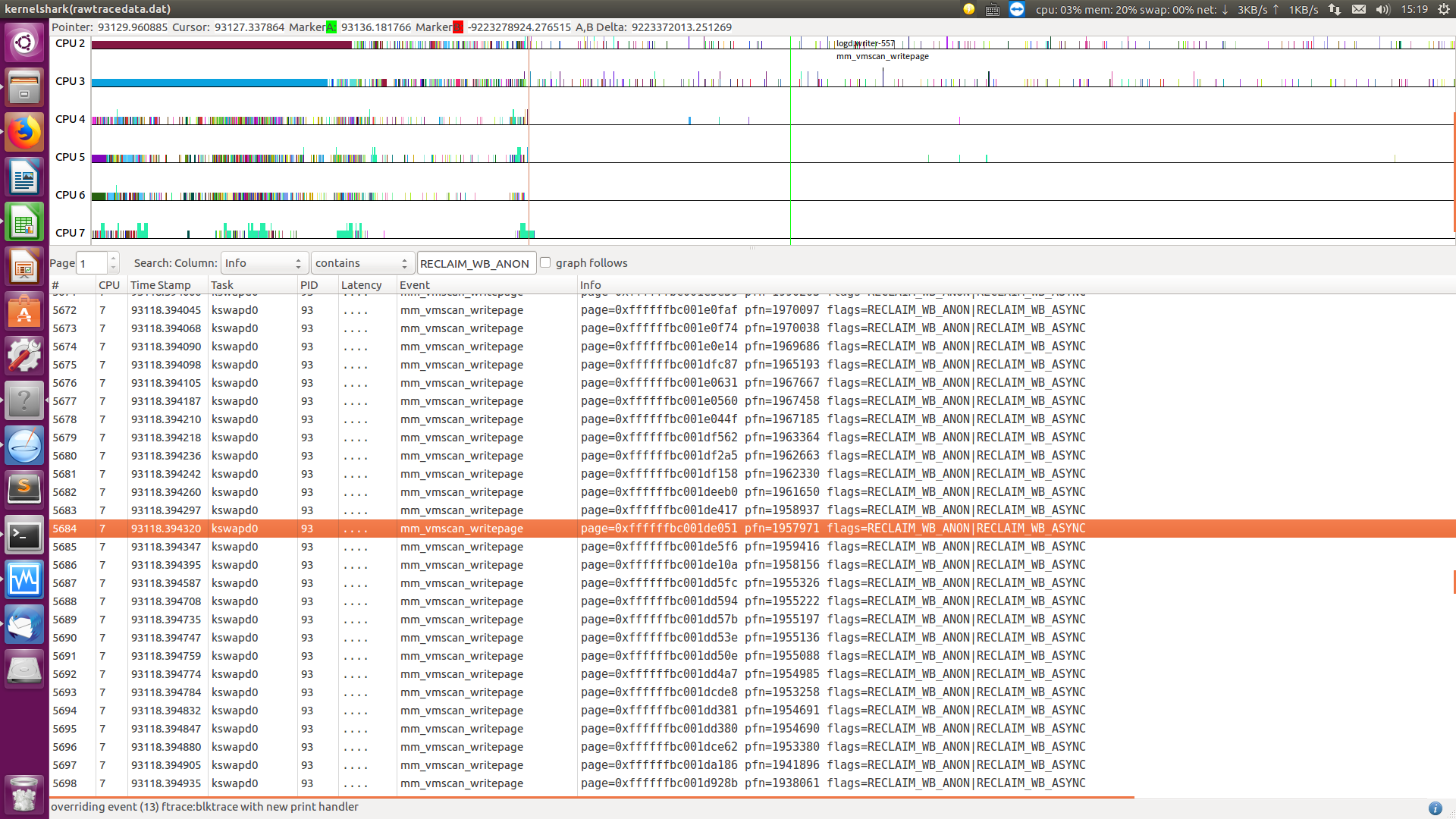
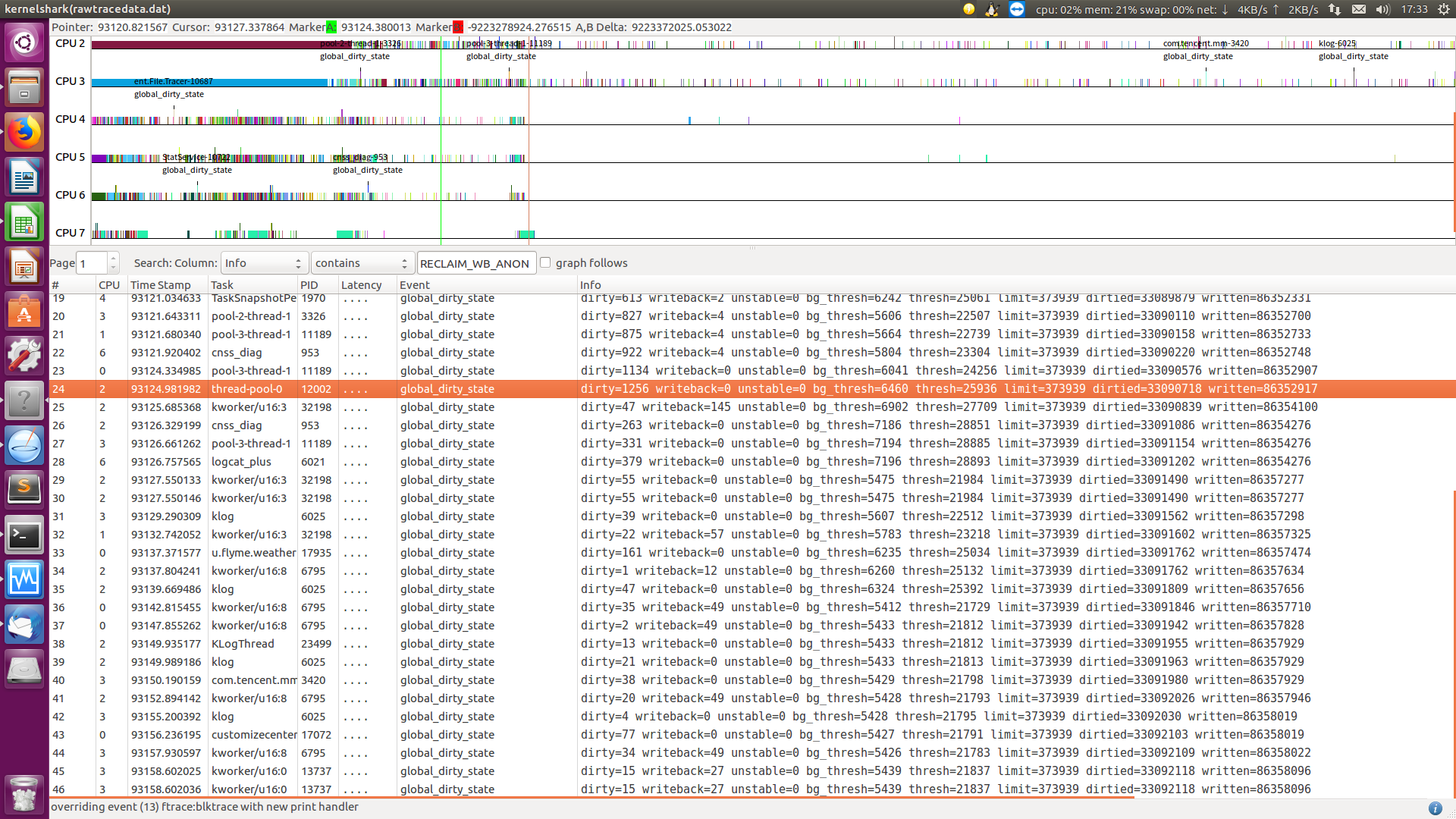
* shrink_page_list() returns the number of reclaimed pages
*/
static unsigned long shrink_page_list(struct list_head *page_list,
struct pglist_data *pgdat,
struct scan_control *sc,
enum ttu_flags ttu_flags,
struct reclaim_stat *stat,
bool force_reclaim)
{
LIST_HEAD(ret_pages);
LIST_HEAD(free_pages);
int pgactivate = 0;
unsigned nr_unqueued_dirty = 0;
unsigned nr_dirty = 0;
unsigned nr_congested = 0;
unsigned nr_reclaimed = 0;
unsigned nr_writeback = 0;
unsigned nr_immediate = 0;
unsigned nr_ref_keep = 0;
unsigned nr_unmap_fail = 0;
cond_resched();
while (!list_empty(page_list)) {
struct address_space *mapping;
struct page *page;
int may_enter_fs;
enum page_references references = PAGEREF_RECLAIM;
bool dirty, writeback;
cond_resched();
page = lru_to_page(page_list);
list_del(&page->lru);
if (!trylock_page(page))
goto keep;
VM_BUG_ON_PAGE(PageActive(page), page);
if (pgdat)
VM_BUG_ON_PAGE(page_pgdat(page) != pgdat, page);
sc->nr_scanned++;
if (unlikely(!page_evictable(page)))
goto activate_locked;
if (!sc->may_unmap && page_mapped(page))
goto keep_locked;
if ((page_mapped(page) || PageSwapCache(page)) &&
!(PageAnon(page) && !PageSwapBacked(page)))
sc->nr_scanned++;
may_enter_fs = (sc->gfp_mask & __GFP_FS) ||
(PageSwapCache(page) && (sc->gfp_mask & __GFP_IO));
* The number of dirty pages determines if a node is marked
* reclaim_congested which affects wait_iff_congested. kswapd
* will stall and start writing pages if the tail of the LRU
* is all dirty unqueued pages.
*/
page_check_dirty_writeback(page, &dirty, &writeback);
if (dirty || writeback)
nr_dirty++;
if (dirty && !writeback)
nr_unqueued_dirty++;
* Treat this page as congested if the underlying BDI is or if
* pages are cycling through the LRU so quickly that the
* pages marked for immediate reclaim are making it to the
* end of the LRU a second time.
*/
mapping = page_mapping(page);
if (((dirty || writeback) && mapping &&
inode_write_congested(mapping->host)) ||
(writeback && PageReclaim(page)))
nr_congested++;
* If a page at the tail of the LRU is under writeback, there
* are three cases to consider.
*
* 1) If reclaim is encountering an excessive number of pages
* under writeback and this page is both under writeback and
* PageReclaim then it indicates that pages are being queued
* for IO but are being recycled through the LRU before the
* IO can complete. Waiting on the page itself risks an
* indefinite stall if it is impossible to writeback the
* page due to IO error or disconnected storage so instead
* note that the LRU is being scanned too quickly and the
* caller can stall after page list has been processed.
*
* 2) Global or new memcg reclaim encounters a page that is
* not marked for immediate reclaim, or the caller does not
* have __GFP_FS (or __GFP_IO if it's simply going to swap,
* not to fs). In this case mark the page for immediate
* reclaim and continue scanning.
*
* Require may_enter_fs because we would wait on fs, which
* may not have submitted IO yet. And the loop driver might
* enter reclaim, and deadlock if it waits on a page for
* which it is needed to do the write (loop masks off
* __GFP_IO|__GFP_FS for this reason); but more thought
* would probably show more reasons.
*
* 3) Legacy memcg encounters a page that is already marked
* PageReclaim. memcg does not have any dirty pages
* throttling so we could easily OOM just because too many
* pages are in writeback and there is nothing else to
* reclaim. Wait for the writeback to complete.
*
* In cases 1) and 2) we activate the pages to get them out of
* the way while we continue scanning for clean pages on the
* inactive list and refilling from the active list. The
* observation here is that waiting for disk writes is more
* expensive than potentially causing reloads down the line.
* Since they're marked for immediate reclaim, they won't put
* memory pressure on the cache working set any longer than it
* takes to write them to disk.
*/
if (PageWriteback(page)) {
if (current_is_kswapd() &&
PageReclaim(page) &&
(pgdat &&
test_bit(PGDAT_WRITEBACK, &pgdat->flags))) {
nr_immediate++;
goto activate_locked;
} else if (sane_reclaim(sc) ||
!PageReclaim(page) || !may_enter_fs) {
* This is slightly racy - end_page_writeback()
* might have just cleared PageReclaim, then
* setting PageReclaim here end up interpreted
* as PageReadahead - but that does not matter
* enough to care. What we do want is for this
* page to have PageReclaim set next time memcg
* reclaim reaches the tests above, so it will
* then wait_on_page_writeback() to avoid OOM;
* and it's also appropriate in global reclaim.
*/
SetPageReclaim(page);
nr_writeback++;
goto activate_locked;
} else {
unlock_page(page);
wait_on_page_writeback(page);
list_add_tail(&page->lru, page_list);
continue;
}
}
if (!force_reclaim)
references = page_check_references(page, sc);
switch (references) {
case PAGEREF_ACTIVATE:
goto activate_locked;
case PAGEREF_KEEP:
nr_ref_keep++;
goto keep_locked;
case PAGEREF_RECLAIM:
case PAGEREF_RECLAIM_CLEAN:
;
}
* Anonymous process memory has backing store?
* Try to allocate it some swap space here.
* Lazyfree page could be freed directly
*/
if (PageAnon(page) && PageSwapBacked(page)) {
if (!PageSwapCache(page)) {
if (!(sc->gfp_mask & __GFP_IO))
goto keep_locked;
if (PageTransHuge(page)) {
if (!can_split_huge_page(page, NULL))
goto activate_locked;
* Split pages without a PMD map right
* away. Chances are some or all of the
* tail pages can be freed without IO.
*/
if (!compound_mapcount(page) &&
split_huge_page_to_list(page,
page_list))
goto activate_locked;
}
if (!add_to_swap(page)) {
if (!PageTransHuge(page))
goto activate_locked;
if (split_huge_page_to_list(page,
page_list))
goto activate_locked;
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
count_vm_event(THP_SWPOUT_FALLBACK);
#endif
if (!add_to_swap(page))
goto activate_locked;
}
may_enter_fs = 1;
mapping = page_mapping(page);
}
} else if (unlikely(PageTransHuge(page))) {
if (split_huge_page_to_list(page, page_list))
goto keep_locked;
}
* The page is mapped into the page tables of one or more
* processes. Try to unmap it here.
*/
if (page_mapped(page)) {
enum ttu_flags flags = ttu_flags | TTU_BATCH_FLUSH;
if (unlikely(PageTransHuge(page)))
flags |= TTU_SPLIT_HUGE_PMD;
if (!try_to_unmap(page, flags, sc->target_vma)) {
nr_unmap_fail++;
goto activate_locked;
}
}
if (PageDirty(page)) {
* Only kswapd can writeback filesystem pages
* to avoid risk of stack overflow. But avoid
* injecting inefficient single-page IO into
* flusher writeback as much as possible: only
* write pages when we've encountered many
* dirty pages, and when we've already scanned
* the rest of the LRU for clean pages and see
* the same dirty pages again (PageReclaim).
*/
if (page_is_file_cache(page) &&
(!current_is_kswapd() || !PageReclaim(page) ||
(pgdat &&
!test_bit(PGDAT_DIRTY, &pgdat->flags)))) {
* Immediately reclaim when written back.
* Similar in principal to deactivate_page()
* except we already have the page isolated
* and know it's dirty
*/
inc_node_page_state(page, NR_VMSCAN_IMMEDIATE);
SetPageReclaim(page);
goto activate_locked;
}
if (references == PAGEREF_RECLAIM_CLEAN)
goto keep_locked;
if (!may_enter_fs)
goto keep_locked;
if (!sc->may_writepage)
goto keep_locked;
* Page is dirty. Flush the TLB if a writable entry
* potentially exists to avoid CPU writes after IO
* starts and then write it out here.
*/
try_to_unmap_flush_dirty();
switch (pageout(page, mapping, sc)) {
case PAGE_KEEP:
goto keep_locked;
case PAGE_ACTIVATE:
goto activate_locked;
case PAGE_SUCCESS:
if (PageWriteback(page))
goto keep;
if (PageDirty(page))
goto keep;
* A synchronous write - probably a ramdisk. Go
* ahead and try to reclaim the page.
*/
if (!trylock_page(page))
goto keep;
if (PageDirty(page) || PageWriteback(page))
goto keep_locked;
mapping = page_mapping(page);
case PAGE_CLEAN:
;
}
}
* If the page has buffers, try to free the buffer mappings
* associated with this page. If we succeed we try to free
* the page as well.
*
* We do this even if the page is PageDirty().
* try_to_release_page() does not perform I/O, but it is
* possible for a page to have PageDirty set, but it is actually
* clean (all its buffers are clean). This happens if the
* buffers were written out directly, with submit_bh(). ext3
* will do this, as well as the blockdev mapping.
* try_to_release_page() will discover that cleanness and will
* drop the buffers and mark the page clean - it can be freed.
*
* Rarely, pages can have buffers and no ->mapping. These are
* the pages which were not successfully invalidated in
* truncate_complete_page(). We try to drop those buffers here
* and if that worked, and the page is no longer mapped into
* process address space (page_count == 1) it can be freed.
* Otherwise, leave the page on the LRU so it is swappable.
*/
if (page_has_private(page)) {
if (!try_to_release_page(page, sc->gfp_mask))
goto activate_locked;
if (!mapping && page_count(page) == 1) {
unlock_page(page);
if (put_page_testzero(page))
goto free_it;
else {
* rare race with speculative reference.
* the speculative reference will free
* this page shortly, so we may
* increment nr_reclaimed here (and
* leave it off the LRU).
*/
nr_reclaimed++;
continue;
}
}
}
if (PageAnon(page) && !PageSwapBacked(page)) {
if (!page_ref_freeze(page, 1))
goto keep_locked;
if (PageDirty(page)) {
page_ref_unfreeze(page, 1);
goto keep_locked;
}
count_vm_event(PGLAZYFREED);
count_memcg_page_event(page, PGLAZYFREED);
} else if (!mapping || !__remove_mapping(mapping, page, true))
goto keep_locked;
* At this point, we have no other references and there is
* no way to pick any more up (removed from LRU, removed
* from pagecache). Can use non-atomic bitops now (and
* we obviously don't have to worry about waking up a process
* waiting on the page lock, because there are no references.
*/
__ClearPageLocked(page);
free_it:
nr_reclaimed++;
* Is there need to periodically free_page_list? It would
* appear not as the counts should be low
*/
if (unlikely(PageTransHuge(page))) {
mem_cgroup_uncharge(page);
(*get_compound_page_dtor(page))(page);
} else
list_add(&page->lru, &free_pages);
* If pagelist are from multiple nodes, we should decrease
* NR_ISOLATED_ANON + x on freed pages in here.
*/
if (!pgdat)
dec_node_page_state(page, NR_ISOLATED_ANON +
page_is_file_cache(page));
continue;
activate_locked:
if (PageSwapCache(page) && (mem_cgroup_swap_full(page) ||
PageMlocked(page)))
try_to_free_swap(page);
VM_BUG_ON_PAGE(PageActive(page), page);
if (!PageMlocked(page)) {
SetPageActive(page);
pgactivate++;
count_memcg_page_event(page, PGACTIVATE);
}
keep_locked:
unlock_page(page);
keep:
list_add(&page->lru, &ret_pages);
VM_BUG_ON_PAGE(PageLRU(page) || PageUnevictable(page), page);
}
mem_cgroup_uncharge_list(&free_pages);
try_to_unmap_flush();
free_unref_page_list(&free_pages);
list_splice(&ret_pages, page_list);
count_vm_events(PGACTIVATE, pgactivate);
if (stat) {
stat->nr_dirty = nr_dirty;
stat->nr_congested = nr_congested;
stat->nr_unqueued_dirty = nr_unqueued_dirty;
stat->nr_writeback = nr_writeback;
stat->nr_immediate = nr_immediate;
stat->nr_activate = pgactivate;
stat->nr_ref_keep = nr_ref_keep;
stat->nr_unmap_fail = nr_unmap_fail;
}
return nr_reclaimed;
}